
话不多说,来个图
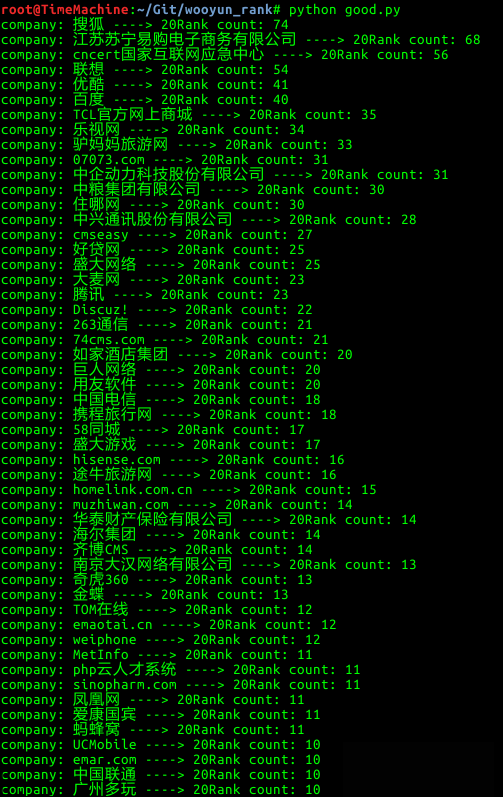
代码托管在github,链接在这 wooyun_rank
具体实现的过程简单整理一下发上来,都很简单,代码也很容易理解
首先是需要获取总页数多少
def getPageCount(url):
url = url+’1′
header = {“User-Agent”:”Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0″}
wooyunUrlList = []
try:
req = requests.get(url = url,headers = header,timeout = 5)
htmlcode = req.content.replace(‘\r\n’,”)
pageCount = int(re.findall(r’录, (.+?) 页’,htmlcode)[0])
return pageCount
except Exception,e:
sys.exit(‘[e] Error, exception is %s’ % e)
页数的获取从第一页就能得到,所以请求一次便可,这里需要注意的是
header = {“User-Agent”:”Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0″}
因为乌云使用了百度云加速,如果没有加上Headers,会被百度云加速拦截。
req.content.replace(‘\r\n’,”)
这段代码是将取回内容中的换行符全部替换掉便于正确的匹配字符串。
int(re.findall(r’录, (.+?) 页’,htmlcode)[0])
这段代码就很简单了,使用re正则匹配页数的字符串,再转换成整型。
def getVulInfo(url):
header = {“User-Agent”:”Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0″}
try:
req = requests.get(url = url,headers = header,timeout = 10)
result = req.content.replace(‘\r\n’,”)
title = re.findall(r”漏洞标题:(.+?)<“,result)[0]
title = ”.join(title.split())
title = unicode(title)
status = re.findall(r”漏洞状态:(.+?)<“,result)[0]
status = ”.join(status.split())
status = unicode(status)
if ‘忽略’ in status:
rank = ‘0’
else:
rank = re.findall(r”漏洞Rank:(.+?)<“,result)[0]
rank = ”.join(rank.split())
vultype = re.findall(r”漏洞类型:(.+?)<“,result)[0]
vultype = ”.join(vultype.split())
vultype = unicode(vultype)
sumittime = re.findall(r”提交时间:(.+?)<“,result)[0]
sumittime = sumittime.replace(‘\t’,”)
publishtime = re.findall(r”公开时间:(.+?)<“,result)[0]
publishtime = publishtime.replace(‘\t’,”)
author = re.findall(r”漏洞作者:(.+?)</h3>”,result)[0]
author = re.findall(r’>(.+?)<‘,author)[0]
author = ”.join(author.split())
author = unicode(author)
company = re.findall(r”相关厂商:(.+?)</h3>”,result)[0]
company = re.findall(r’>(.+?)<‘,company)[0]
company = ”.join(company.split())
company = unicode(company)
try:
cx = sqlite3.connect(sys.path[0]+”/wooyun.db”)
cu = cx.cursor()
cu.execute(“select * from record where url = ‘”+ url +”‘”)
if not cu.fetchone():
cu.execute(“insert into record (title,url,company,status,author,vultype,rank,sumittime,publishtime) values (?,?,?,?,?,?,?,?,?)”, (title,url,company,status,author,vultype,rank,sumittime,publishtime))
cx.commit()
print ‘[+] Insert ‘+url+’ into database successly.’
else:
print ‘[-] Found ‘+url+’ in database, skipped.’
cu.close()
cx.close()
except Exception, e:
print e
except Exception,e:
print e
pass
获取具体漏洞信息的代码就是这些了,大部分还是使用re正则匹配相关字符串,需要注意的是编码问题,头部先声明
reload(sys)
sys.setdefaultencoding(‘utf8’)
然后将过滤到的字符串进行unicode编码,这样做的目的是因为sqlite3进行存储的时候如果不是unicode编码会导致乱码。
- 本文固定链接: https://www.oyblog.cn/OuYang-Blog-520192.html
- 转载请注明: OuYang-Blog(www.oyblog.cn)